
作者: afenxi来源: afenxi时间:2017-03-28 10:38:240
提问:从业者们自己是如何理解【大数据[email protected]
谢谢提问!
我谈谈对大数据分析的理解,这要从什么是大数据讲起。
因为从事这一方向,经常会有人问我什么是大数据?我一直都回答不好。在最近的几个月,我对这一概念思考的更多一些,结合看过的一些书籍(如《大数据时代》、《数学之美》第二版等)和实际的经历,算是有了一些认识,今天我就从大数据的概念开始讲起,试图给大家讲清楚什么是大数据分析。
首先,我来谈谈我对大数据的理解,分为大数据概念和大数据思维。
我把大数据的概念总结为四个字:大、全、细、时。
我们先来看一组数据:
百度每天采集的用户行为数据有1.5PB以上 全国各地级市今天的苹果价格数据有2MB 1998年Google抓取的互联网页面共有47GB(压缩后) 一台风力发电机每天产生的振动数据有50GB
百度每天的行为数据1.5个PB够大吧?我们毫无怀疑这是大数据。但全国各个地级市今天的苹果价格只有2MB大小,是典型的小数据吧?但如果我们基于这个数据,做一个苹果分销的智能调度系统,这就是个牛逼的大数据应用了。Google在刚成立的时候,佩奇和布林下载了整个互联网的页面,在压缩后也就47GB大小,现在一个U盘都能装的下,但Google搜索显然是个大数据的应用。如果再来看一台风机每天的振动数据可能都有50GB,但这个数据只是针对这一台风机的,并不能从覆盖面上,起到多大的作用,这我认为不能叫大数据。
这里就是在强调大,是Big不是Large,我们强调的是抽象意义的大。
我们再来看关于美国大选的三次事件:
1936年《文学文摘》收集了240万份调查问卷,预测错误 新闻学教授盖洛普只收集了5万人的意见,预测罗斯福连任正确 2012年Nate Silver通过互联网采集社交、新闻数据,预测大选结果
《文学文摘》所收集的问卷有240万,绝对是够大的,但为什么预测错误了呢?当时《文学文摘》是通过电话调查的,能够装电话的就是一类富人,这类人本身就有不同的政治倾向,调查的结果本身就是偏的。而盖洛普只收集了5万人的意见,但是他采用按照社会人群按照比例抽样,然后汇集总体结果,反而预测正确了。因为这次预测,盖洛普一炮而红,现在成了一个著名的调研公司。当然,后来盖洛普也有预测失败的时候。到了2012年,一个名不见经传的人物Nate Silver通过采集网上的社交、新闻数据,这是他预测的情况和真实的情况:
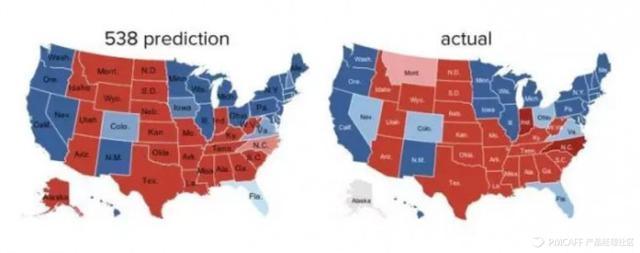 两者是惊人的接近的。
两者是惊人的接近的。
从这点我是想强调要全量而不是抽样,大数据时代有了更好的数据采集手段,让获取全量数据成为可能。
在2013年9月,百度知道发布了一份《中国十大吃货省市排行榜》,在关于“××能吃吗?”的问题中,宁夏网友最关心“螃蟹能吃吗?”内蒙古、新疆和西藏的人最关心“蘑菇能吃吗?”浙江、广东、福建、四川等地网友问得最多的是“××虫能吃吗?”而江苏以及上海、北京等地则最爱问“××的皮能不能吃?”。下图是全国各地关心的食物:
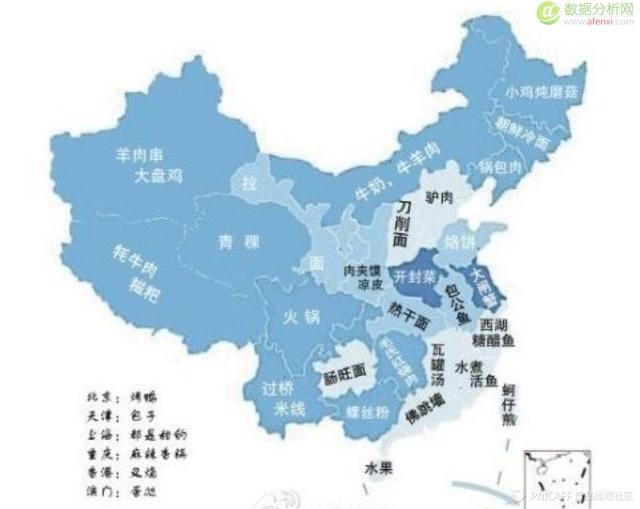 用户在问什么能吃吗的时候,并不会说“我来自宁夏,我想知道螃蟹能吃吗”,而是会问“螃蟹能吃吗”,但是服务器采集到了用户的IP地址,而通过IP地址就能知道他所在的省份。这就是数据多维度的威力,如果没有IP这个维度,这个分析就不好办了。而现有的采集手段,能够让我们从多个维度获取数据,再进行后续分析的时候,就能对这些维度加以利用,就是“细”。
用户在问什么能吃吗的时候,并不会说“我来自宁夏,我想知道螃蟹能吃吗”,而是会问“螃蟹能吃吗”,但是服务器采集到了用户的IP地址,而通过IP地址就能知道他所在的省份。这就是数据多维度的威力,如果没有IP这个维度,这个分析就不好办了。而现有的采集手段,能够让我们从多个维度获取数据,再进行后续分析的时候,就能对这些维度加以利用,就是“细”。
我们现在对CPI已经不再陌生,是居民消费价格指数(consumer price index)的简称。我们努力工作,起码要跑过CPI。
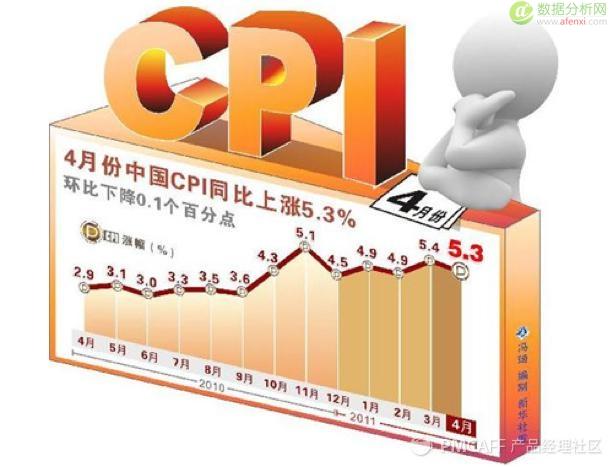 那你有了解过CPI是怎么统计的吗?这里包括两个阶段,一个是收集商品价格数据,一个是分析并发布数据。我从百度百科上了解到,中国CPI采样500多个市县,采价调查点6.3万个,近4000名采价员,次月中旬发布报告。我还曾找国家统计局的朋友确认了这个事情。
那你有了解过CPI是怎么统计的吗?这里包括两个阶段,一个是收集商品价格数据,一个是分析并发布数据。我从百度百科上了解到,中国CPI采样500多个市县,采价调查点6.3万个,近4000名采价员,次月中旬发布报告。我还曾找国家统计局的朋友确认了这个事情。
而在美国有一家创业公司叫Premise Data。它通过众包方式,25000个采价员(学生、收银员、司机等),使用手机APP采集数据,每条6~40美分,比美国政府数据提前4~6周发布。
这就是“时”,强调实时收集数据和实时分析数据。当然,在CPI的例子中,我们可以让价格上报更智能一些,不需要人工的方式。
从上面的大、全、细、时四个字,我们就可以对大数据的概念有个较为清晰的认识。这四点主要强调的数据的获取和规模上,和以往传统数据时代的差异。有了这个基础,我们还要看怎么对大数据加以利用。这里就要看看大数据思维。我们也来看两个例子。
85前应该都用过智能ABC,一种古老的输入法,打起来特别慢。到了2002年左右,出了一个叫紫光的输入法,当时我就震惊了。真的输入很快,仿佛你的按键还没按下去,字就已经跳出来了。但渐渐的发现紫光拼音有个问题是许多新的词汇它没有。后来有了搜狗输入法,直接基于搜索的用户搜索记录,去抽取新的词库,准实时的更新用户本地的词库数据,因为有了大量的输入数据,就能直接识别出最可能的组合。
我们以前都用纸质的地图,每年还要买新的,旧的地址可能会过时,看着地图你绝对不知道哪里堵车。但有了百度地图就不一样了,我们上面搜索的地址都是及时更新的,虽然偶尔也会有被带到沟里的情况,但毕竟是少数。可以实时的看到路面堵车情况,并且可以规划防拥堵路线。
我们想想这种做事方式和以前有和不同?
我们发现不是在拍脑袋做决定了,不是通过因果关系或者规则来决定该怎么办了,而是直接通过数据要答案。我们获取的数据越全面,越能消除更多的不确定性。也就是用数据说话,数据驱动。
在百度文化的29条中,我第二认可的一条就是“用数据说话”,数据有时候也会欺骗人,但大部分时候它还是客观冷静的,不带有感情色彩。据说在硅谷用数据说话都是一种很自然的工作习惯,但你放眼望去你周围,你会发现许多没有数据的例子,拍脑袋的,拼嗓门的,拼关系的,拼职位的,这一点都不科学。
那我们再来看看互联网领域的数据驱动。许多公司的情况是这样的:

 不管是运营、产品、市场、老板,都通过数据工程师老王获取数据,老王忙的痛不欲生。但数据需求方都对数据获取的速度很不满意,有的等不及,还是决定拍脑袋了。这样极大的阻碍的迭代的速度。
不管是运营、产品、市场、老板,都通过数据工程师老王获取数据,老王忙的痛不欲生。但数据需求方都对数据获取的速度很不满意,有的等不及,还是决定拍脑袋了。这样极大的阻碍的迭代的速度。
还有的公司情况是这样的:

 对老板来说,有个仪表盘还不错,终于知道公司的总体运营情况了,可以基于总体情况做决策了。但如果发现某天的销售额下跌了20%,肯定是要安排下面的人追查的。对于实际干活的运营、产品同学来说,光看一个宏观的指标是不够的,解决不了问题,还要想办法对数据进行多维度的分析,细粒度的下钻,这是仪表盘解决不了的。
对老板来说,有个仪表盘还不错,终于知道公司的总体运营情况了,可以基于总体情况做决策了。但如果发现某天的销售额下跌了20%,肯定是要安排下面的人追查的。对于实际干活的运营、产品同学来说,光看一个宏观的指标是不够的,解决不了问题,还要想办法对数据进行多维度的分析,细粒度的下钻,这是仪表盘解决不了的。
那么理想的数据驱动应该是什么样子的?应该是人人都能够自助式(Self-Service)的数据分析,每个业务人员和数据之间,有一个强大的工具,而不是苦逼的老王。或者只是能看到数据的冰山一角。在数据源头上,又可以获取到全面的数据。
我们接下来看看现有的解决方案上,离真正的数据驱动还有多远的距离。
常见的方案有三种:
 我们先来看看第三方统计服务,目前国内用的比较多的有三家,友盟、百度统计和TalkingData,他们都类似Google Analytics(简称GA,谷歌分析)。
我们先来看看第三方统计服务,目前国内用的比较多的有三家,友盟、百度统计和TalkingData,他们都类似Google Analytics(简称GA,谷歌分析)。
 这些工具的优势是使用简单,并且免费。
这些工具的优势是使用简单,并且免费。
劣势是有以下几点:
数据源:只能覆盖前端JS/APP SDK记录的数据,无法覆盖服务端和业务数据库的数据; 分析能力:只能覆盖宏观通用分析,使用后还需要数据团队满足运营/产品的各类定制化的需求; 安全:规模稍大一点的公司,不想把核心数据放在第三方平台。
第二种是使用数据库写SQL,这种在创业公司用的比较多:
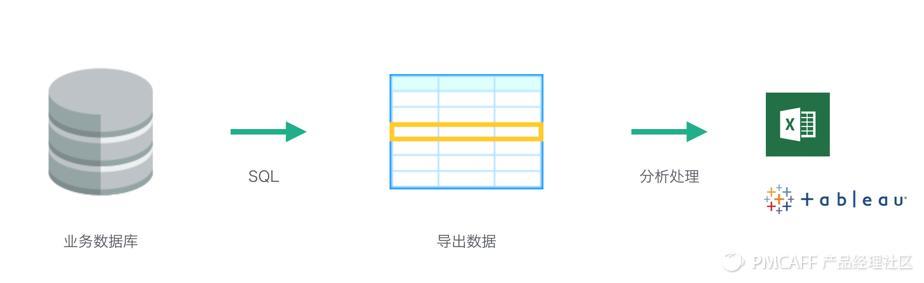 我们直接在业务数据库中写SQL进行查询,然后导出为中间数据,再放到Excel或者其他报表工具上进行绘图分析。这种方式的好处是可以直接分析业务数据库的数据,但最大的不足在数据记录的历史状态被覆盖了。我们用下面的一张图来描述:
我们直接在业务数据库中写SQL进行查询,然后导出为中间数据,再放到Excel或者其他报表工具上进行绘图分析。这种方式的好处是可以直接分析业务数据库的数据,但最大的不足在数据记录的历史状态被覆盖了。我们用下面的一张图来描述:
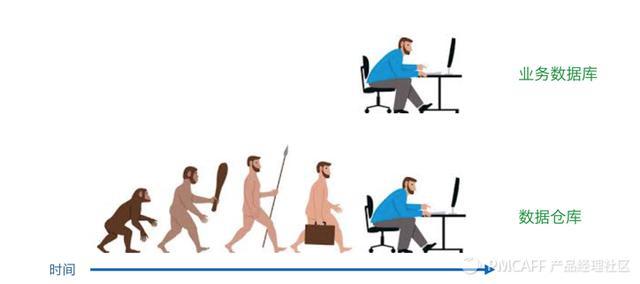 业务数据库是设计用来处理高并发、小批量的用户请求的,而数据仓库强调的是少量查询,但是大批量的。用人类进化的图来说,业务数据库只会存放当前的状态,而数据仓库会存放从猿猴到人的整个过程,原则上说,数据仓库能够恢复到数据库的任一时刻的横切面。
业务数据库是设计用来处理高并发、小批量的用户请求的,而数据仓库强调的是少量查询,但是大批量的。用人类进化的图来说,业务数据库只会存放当前的状态,而数据仓库会存放从猿猴到人的整个过程,原则上说,数据仓库能够恢复到数据库的任一时刻的横切面。
这样你就明白让业务数据库去做数据仓库,是有很多的问题的,这里就不细说了。
第三种方式是基于日志写统计脚本,这种在BAT这样的大公司用的比较普遍,我在百度处理的数据方式主要是这一种。
 这种方式是和业务数据库解耦的,各干各的事。不足是开发效率比较低,准确性也无法保证(没有人去做Code Review、数据Diff)。并且,这是一件很有技术门槛的事,一是打好日志很难,二是数据流的管理很难。有兴趣的可以看我写的系列文章《从日志统计到数据分析》,地址在:http://zhuanlan.zhihu.com/sangwf/20390103。
这种方式是和业务数据库解耦的,各干各的事。不足是开发效率比较低,准确性也无法保证(没有人去做Code Review、数据Diff)。并且,这是一件很有技术门槛的事,一是打好日志很难,二是数据流的管理很难。有兴趣的可以看我写的系列文章《从日志统计到数据分析》,地址在:http://zhuanlan.zhihu.com/sangwf/20390103。
差不多在2012年,在我干了三四年的数据的事情之后,渐渐的认识到数据处理其实就是一条流,并且在以后的实践中不断的坚信这一点。按照数据的流向,可以把数据处理分成5个阶段:
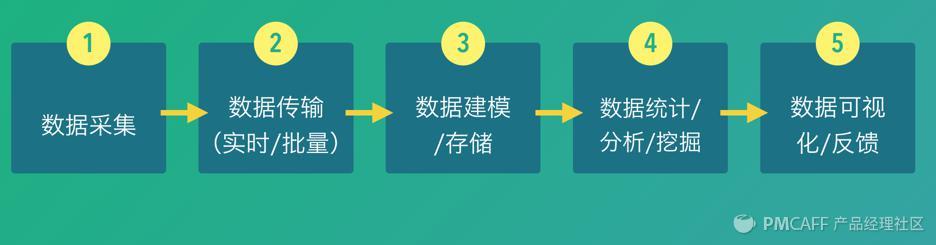 时间关系,我只说一下数据采集、建模两个环节。
时间关系,我只说一下数据采集、建模两个环节。
在百度做了这么多年的大数据,最大的心得就是数据这个事情如果想做好,最重要的就是数据源。数据源想做好,一是要全,一是要细。也就是我在前面讲解大数据概念时提到的其中两点。
数据模型很重要,我们用一个形象的例子:
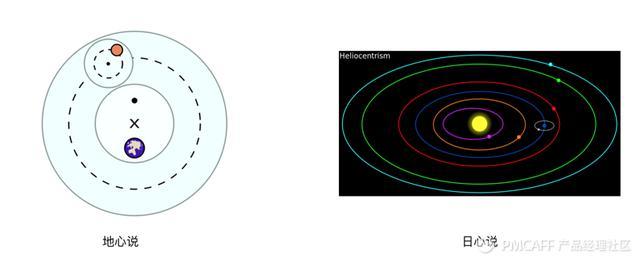 如果按照地心说,需要有40个大圆套小圆,才能演绎九大行星的运行轨迹。但是通过日心说,只要9个椭圆就能搞定了。
如果按照地心说,需要有40个大圆套小圆,才能演绎九大行星的运行轨迹。但是通过日心说,只要9个椭圆就能搞定了。
对于业务数据表,为了达到线上服务的需求,一般会设计成这个样子:
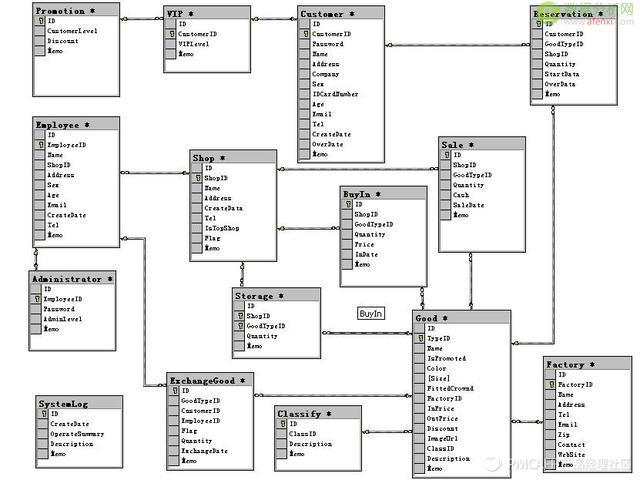 但如果把这个数据模型暴露给业务人员,光理解它都需要几个月,并且中间还在不断变化,变化了相关的SQL任务都要修改。
但如果把这个数据模型暴露给业务人员,光理解它都需要几个月,并且中间还在不断变化,变化了相关的SQL任务都要修改。
这里就要引出数据立方体:
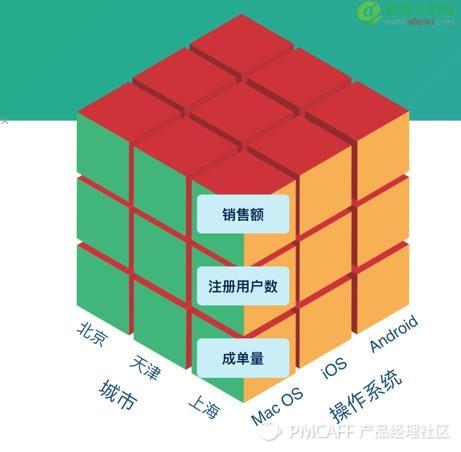 我们可以把数据抽象为维度和指标,像图中的城市和操作系统就是两个维度,而成单量、销售额等就是指标,通过维度的组合,我们可以看这一切片下的数据情况。这只是一个例子,真实的维度可能有几十个,指标可能也有很多。
我们可以把数据抽象为维度和指标,像图中的城市和操作系统就是两个维度,而成单量、销售额等就是指标,通过维度的组合,我们可以看这一切片下的数据情况。这只是一个例子,真实的维度可能有几十个,指标可能也有很多。
通过这种模型,会比较有效的处理用户数据分析的需求。具体来说,我们可以把用户行为抽象为三个部分:
Event Type + Properties + UserID
Event Type表示行为类型,比如提交订单。Properties表示这个行为的相关属性,比如操作系统版本,屏幕宽度,运费,商品ID等。UserID是表示用户。通过UserID,我们又能讲其和用户属性关联起来,包括用户出生日期、性别等。
这里我们看一下一个数据分析平台的总体架构:
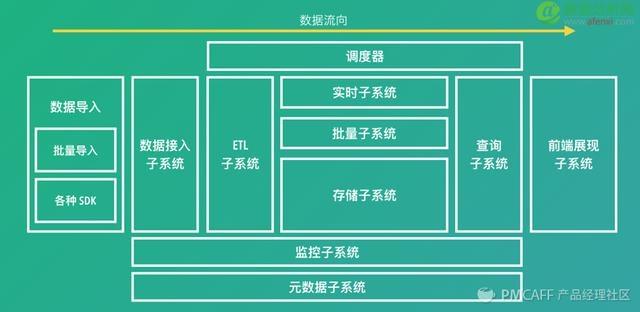 中间部分是上面所说的五个环节。其它还有三个子系统,监控子系统保证整个系统的稳定运行,元数据就像人的心脏,记录了数据的格式、就绪状态。而调度器就像人的大脑,用来管理任务的依赖关系。时间有限,我这里就不详细讲解了。
中间部分是上面所说的五个环节。其它还有三个子系统,监控子系统保证整个系统的稳定运行,元数据就像人的心脏,记录了数据的格式、就绪状态。而调度器就像人的大脑,用来管理任务的依赖关系。时间有限,我这里就不详细讲解了。
如果做到了上面这些,就实现了一套不错的大数据分析平台。这里要说的是,起码需要4~5个有经验的数据工程师,做上半年以上,能做一个60分的产品。
原创文章,作者:桑文锋,如若转载,请注明出处:《从业者们自己是如何理解【大数据分析】的呢?》https://www.afenxi.com/post/7437

永洪BI
更敏捷、更快速、更强大



