1. 页面说明
血缘分析页面可以进行一些查看血缘分析的操作,通过页面上的按钮实现,页面参数如下:
参数 |
说明 |
|---|---|
资源类型 |
资源类型包括门户、报告、实验、数据集。您可以在下拉选择框中选择需要查看的其中一种类型。 |
选择资源 |
根据选择的资源类型,列举符合的资源,当前会展示全部资源,通过下拉列表选择要查看的资源。 |
查询 |
资源选择好以后,点击查询按钮,查询资源的血缘分析结果。 |
显示影响分析 |
勾选上“显示影响分析”后,下方的组织图中会显示其他资源对当前资源的影响数据信息。如报告B被报告A添加了超链接。 |
显示血缘分析 |
勾选上“显示血缘分析”后,下方的组织图中会显示当前资源的血缘数据信息。 |
显示组件节点 |
勾选上“显示组件节点”后,下方的组织图中会显示当前资源的组件节点信息。 |
显示超链接报告 |
勾选上“显示超链接报告”后,下方的组织图中会显示当前资源的超链接报告信息。 |
显示Data Fabric |
勾选上“显示Data Fabric”后,下方的组织图中会显示当前资源引用的资产数据来源信息。 |
刷新 |
点击刷新按钮会刷新资源血缘分析变化后的页面。 |
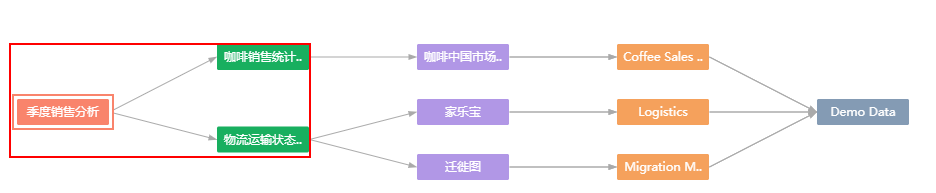
血缘分析页面,不同类型的节点,会按照颜色进行区分,如下图所示。

血缘分析类型 |
参考图 |
|---|---|
数据集 > SQL语句 > 数据源 |
|
数据集 > 数据库表 > 数据源 |
|
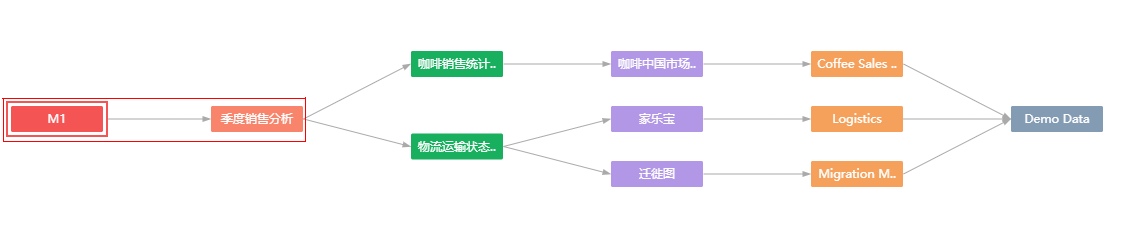
数据集 > 集市文件夹 > 定时任务 > 数据集 > 数据表或SQL语句 > 数据源 |
|
数据集 > 定时任务 > 数据集 > 数据库表 > 数据源 |
|
数据集 > 定时任务 > 数据集 > SQL语句 > 数据源 |
|
数据集 > 数据集 |
|
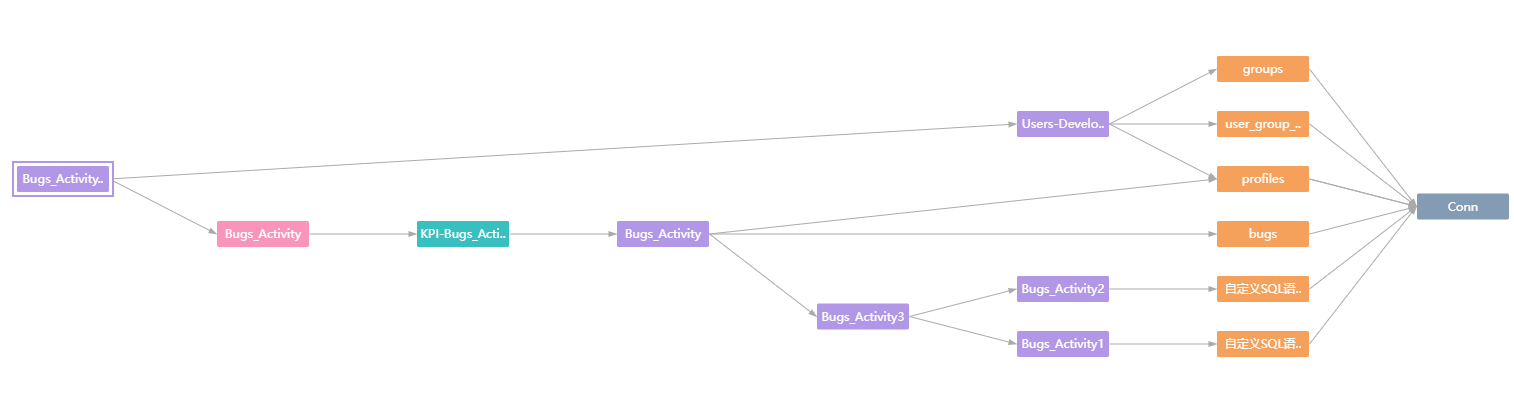
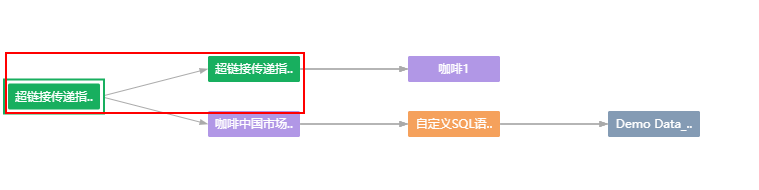
报告 > 超链接报告 |
|
报告 > 组件 > 资产 |
|
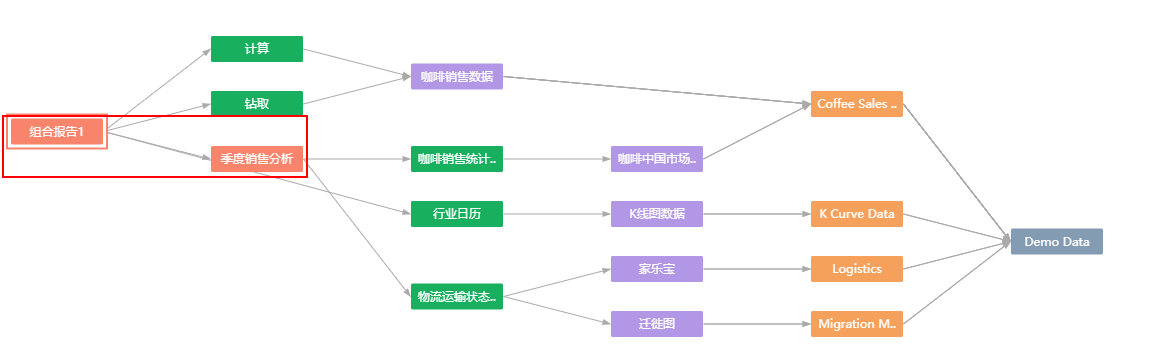
组合报告 > 组合报告 |
|
组合报告 > 网页 |
|
组合报告 > 报告 |
|
普通门户 > 报告 |
|
普通门户 > 组合报告 |
|
普通门户 > 网页 |
|
数据门户 > 组件 |
|







鼠标单击在血缘分析的节点上,会在右侧显示出当前节点的详细信息,详情参考下表。
节点类型 |
详情 |
|---|---|
门户、组合报告、报告、组件、实验、集市文件夹、数据库表 |
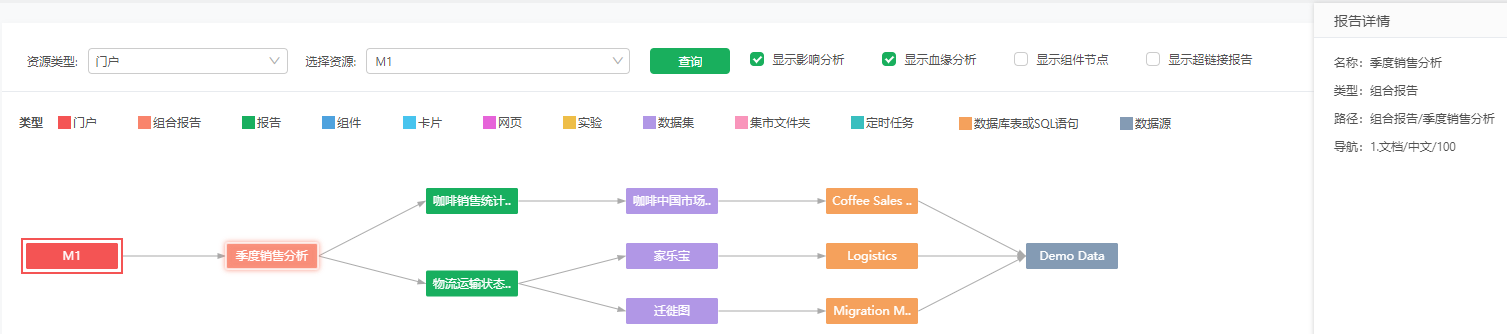
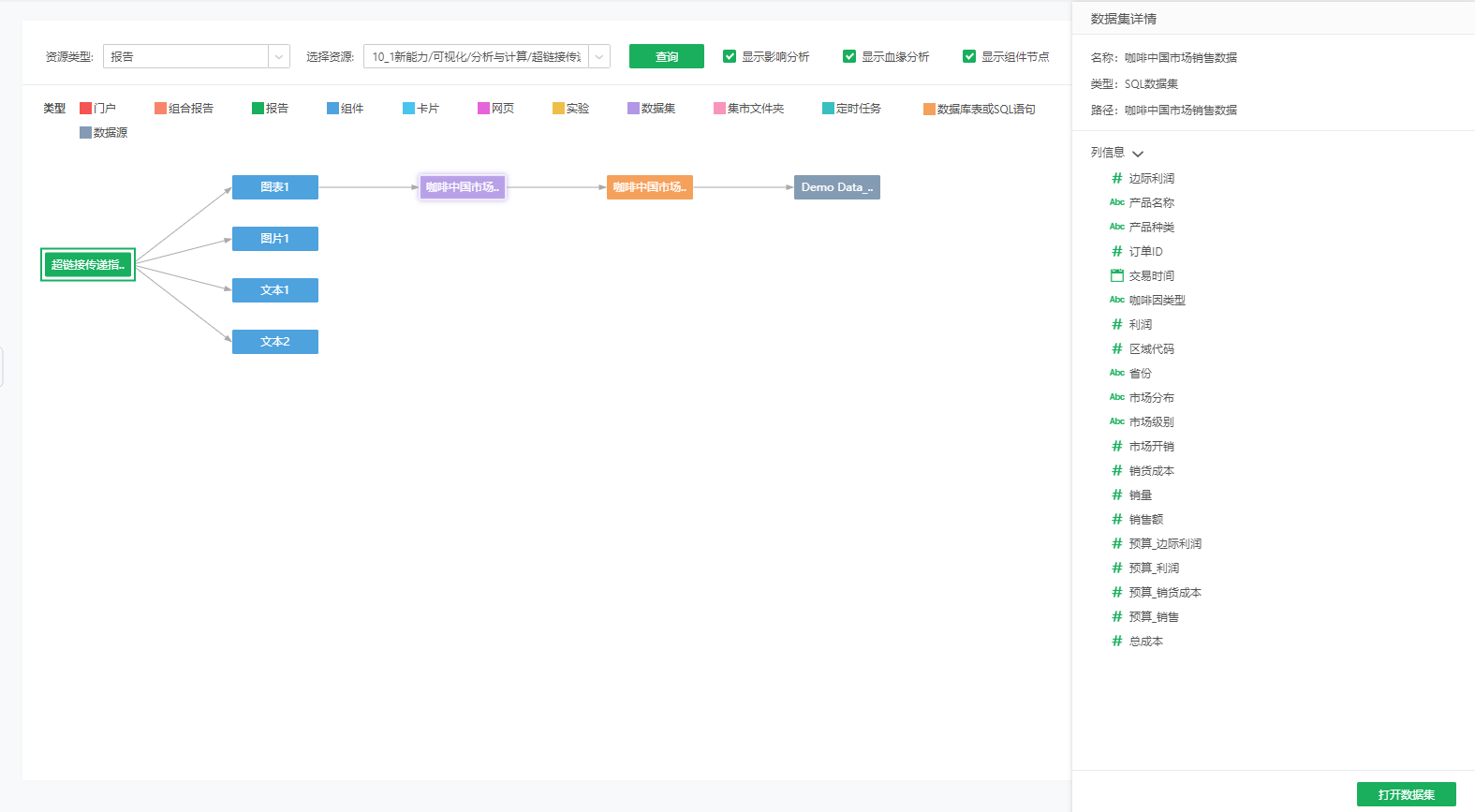
包括名称、类型、路径,参考下图的实验节点。 若报告、组合报告、网页资源添加到普通门户中,还包括导航。 若组件添加到数据门户中,只包括名称和类型,不包括路径。
|
网页 |
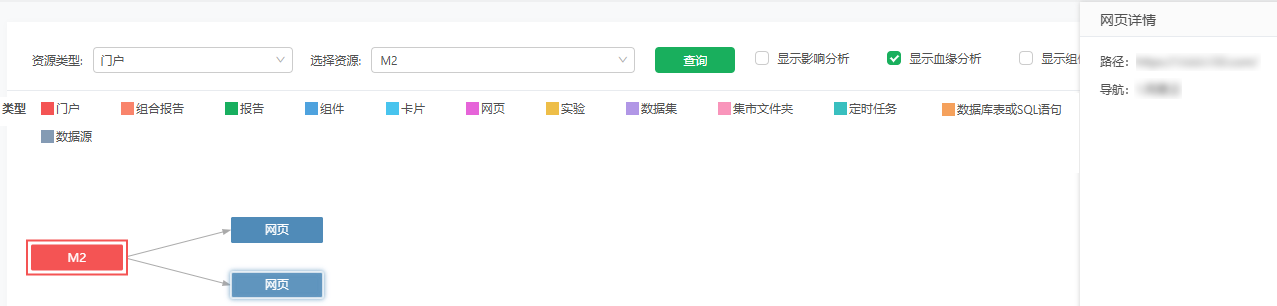
报告、组合报告中的网页只有路径。 若网页添加到普通门户中,还包括导航。
|
组件 |
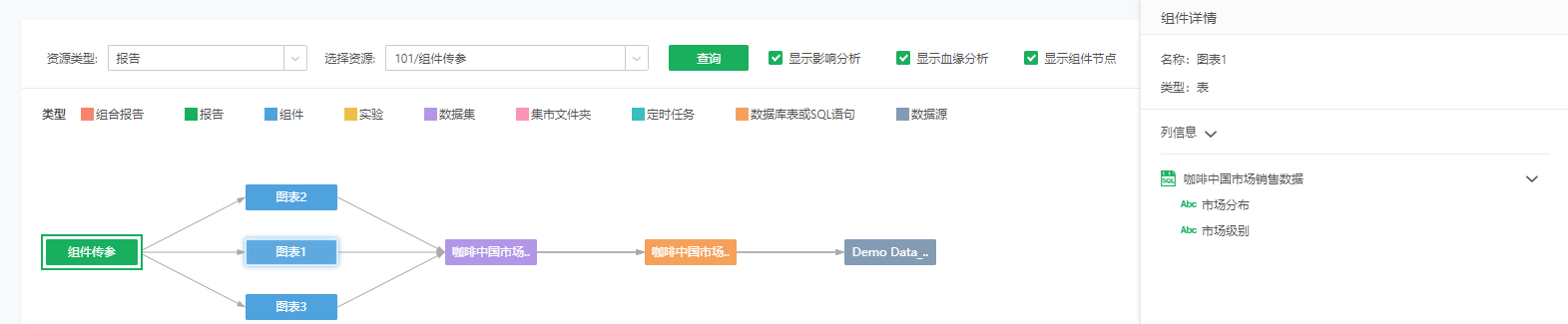
包括组件的名称、类型、用到的字段(包括绑定的普通列,绑定的计算列或表达式列用到的列,过滤、多源过滤里用到的列,绑定的参数列用到的列,绑定的多语言映射列用到的列,数据集抽取数据数据追加时选择的更新依据列)。下图中组件“图表1”为自由式表格,绑定了数据集“咖啡”的省份;数据集“咖啡_副本”的预算_销售;报告上建的计算列“销售额总和”,其中“销售额总和”总和用了字段“销售额”;并用数据集“咖啡_副本”的省份字段做了多源过滤。可以看到列信息显示了三个节点:第一个节点为报告的名称,显示用到的报告上的计算列名称;剩下的节点为数据集的路径,显示用到的数据集的字段。
|
SQL语句 |
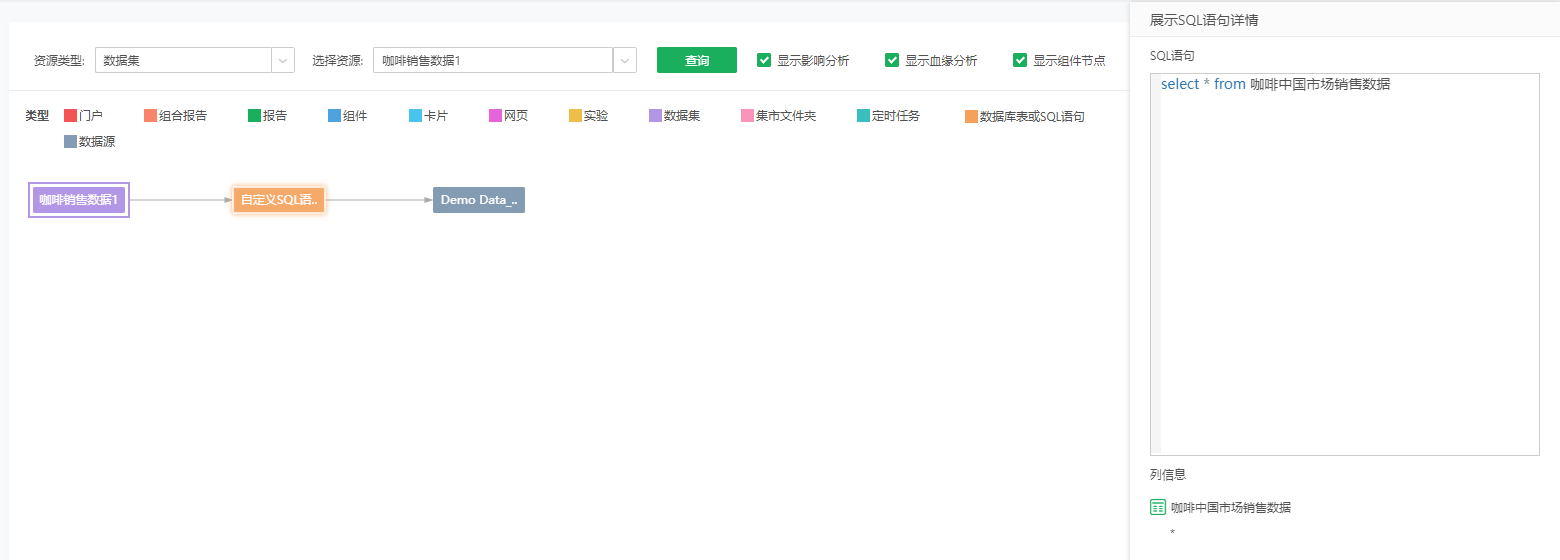
包括SQL语句、SQL的数据库表里的字段 。
|
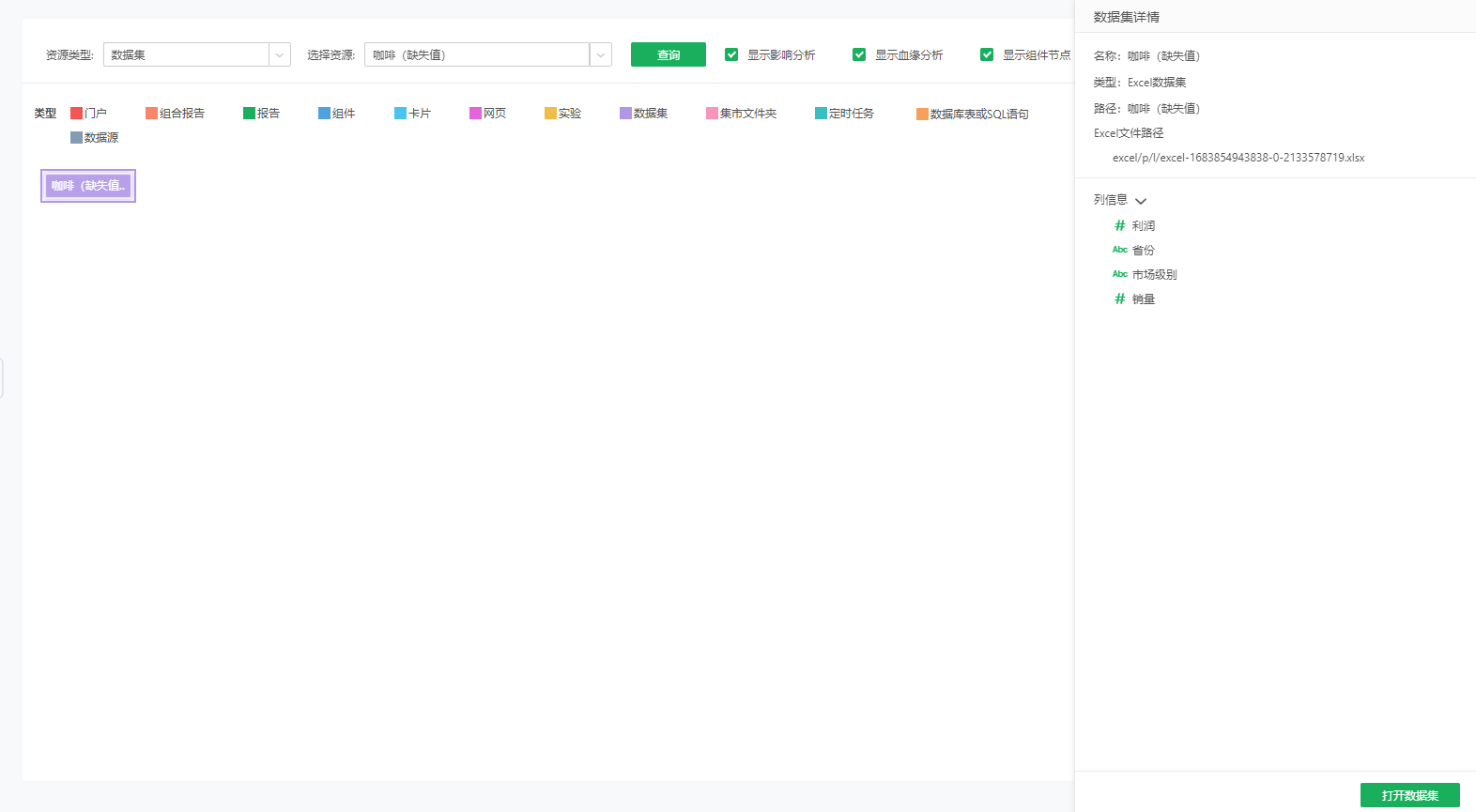
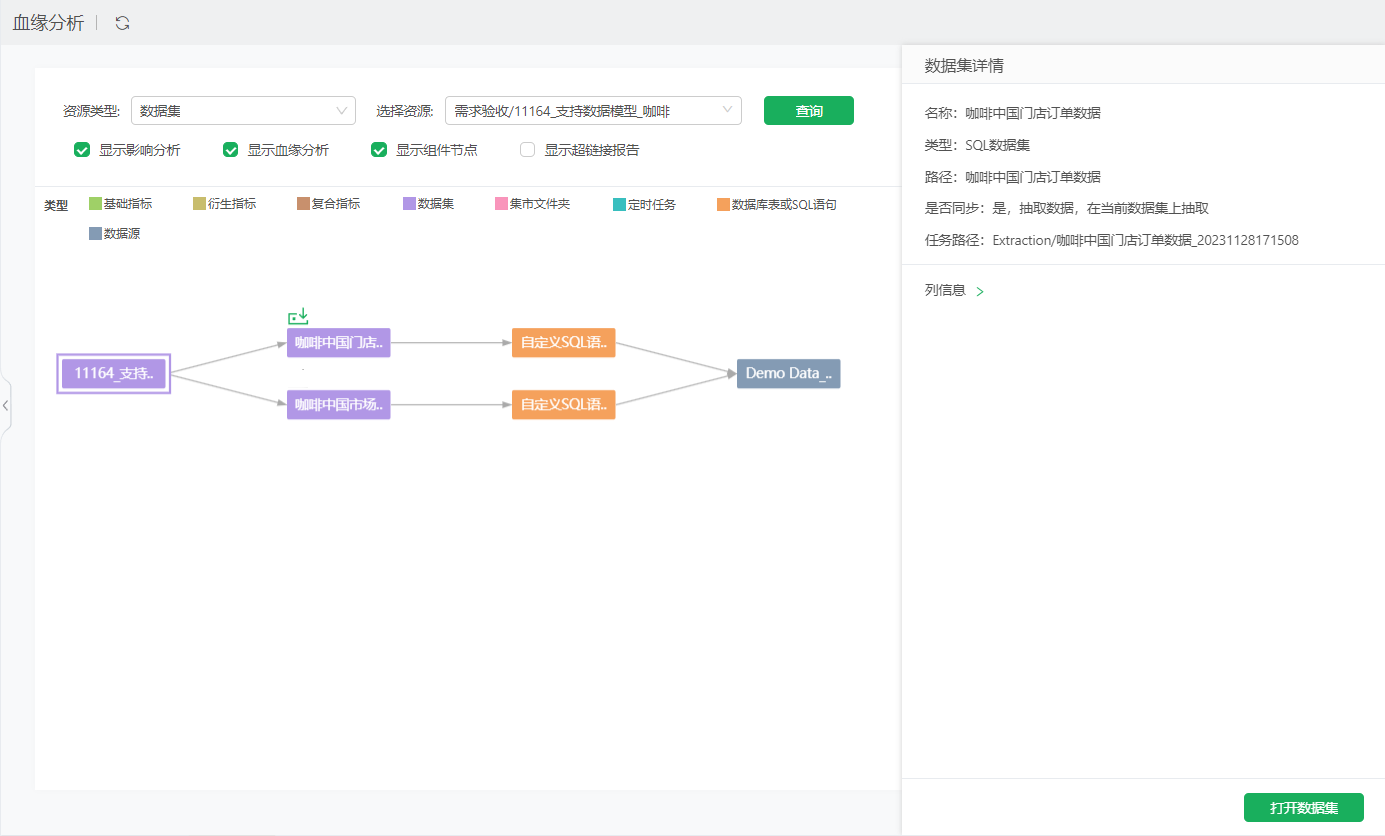
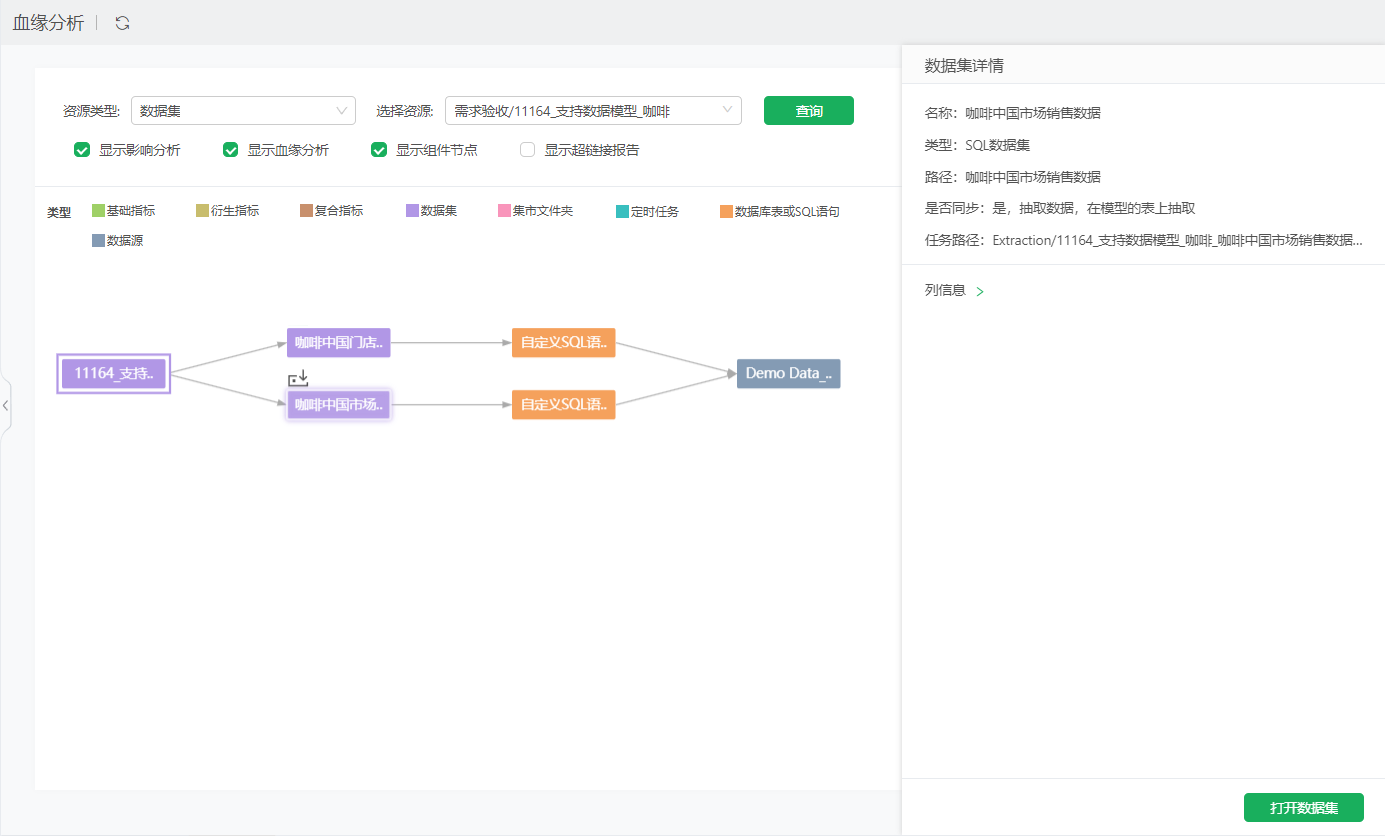
数据集 |
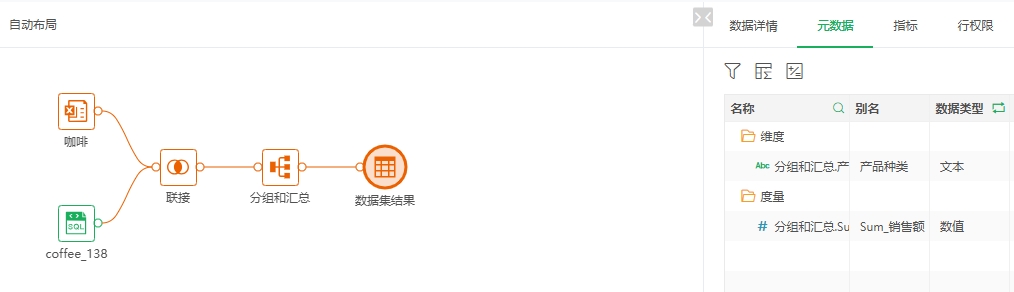
包括名称、类型、路径;如果设置了抽取数据,节点上会显示抽取图标,右侧会显示“是否同步”和“任务路径”;引用详情:可以查看当前查询血缘的资源被其它哪些资源使用;列信息:当前数据集有哪些列,用到了源数据集节点的哪些列;数据集设置了抽取数据,则会显示。对于自服务数据集,凡是中间节点参与计算的列,都会显示到对应的源数据集节点下,包括源数据集节点抽取数据选择追加时用到的更新依据列。点击右下角的打开数据集,可跳转至数据集模块查看、编辑。 下图可以看到“血缘-join”自服务数据集有“Sum_销售额”和“产品种类”字段,用到了“咖啡”数据集的产品种类、订单ID、销售额字段;用到了“coffee_138”数据集的订单ID字段。
“血缘-join”自服务数据集制作如下:其中订单ID为联接节点的联接列,分组和汇总节点用了“咖啡”的“产品种类”和“销售额”字段。
Excel数据集还包括Excel文件路径。
数据模型节点对应的数据集被抽取后显示抽取图标和抽取信息。
数据模型节点被抽取后显示抽取图标和抽取信息。
|
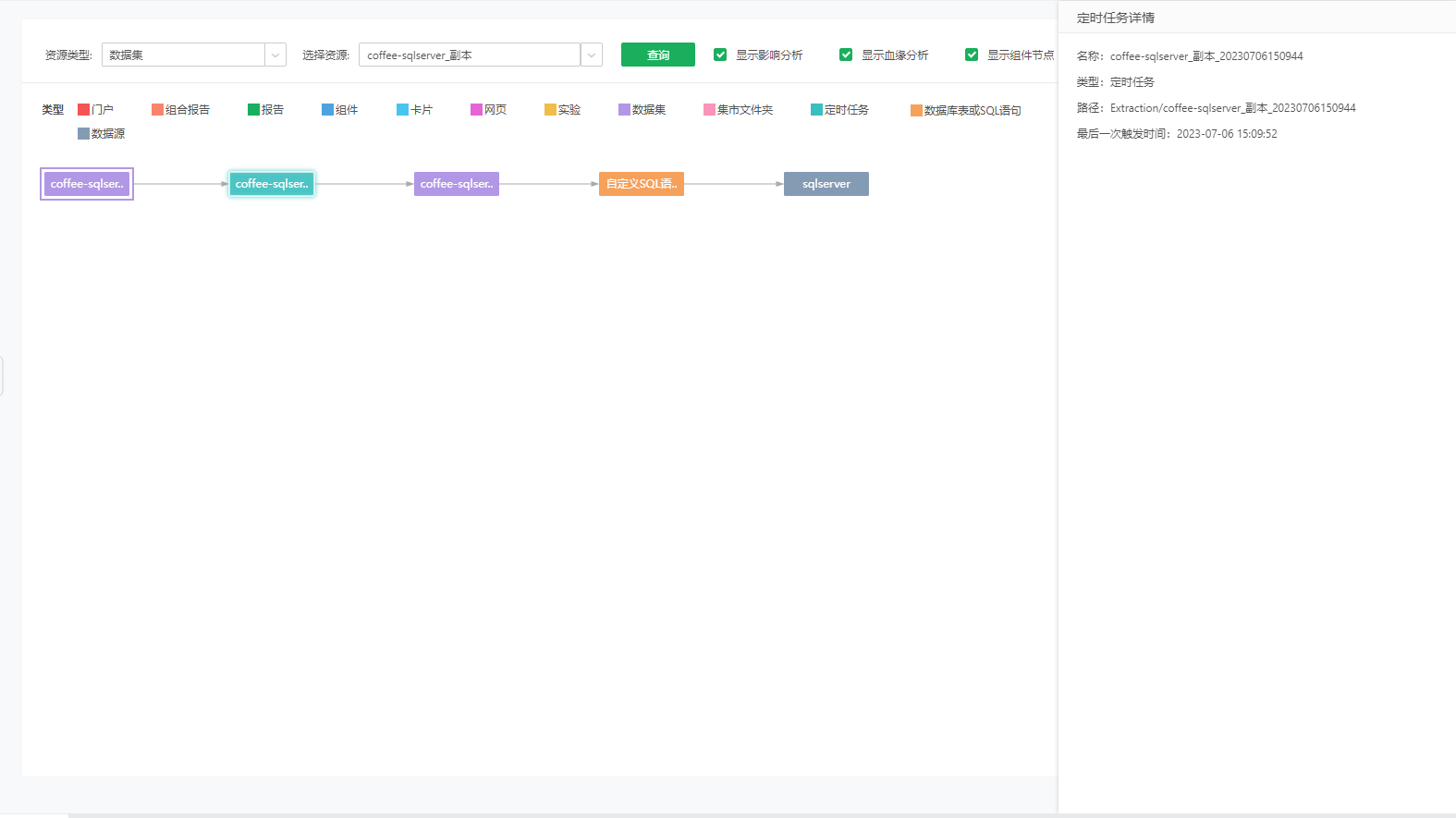
定时任务 |
包括名称、类型、路径、最后一次触发时间。
|
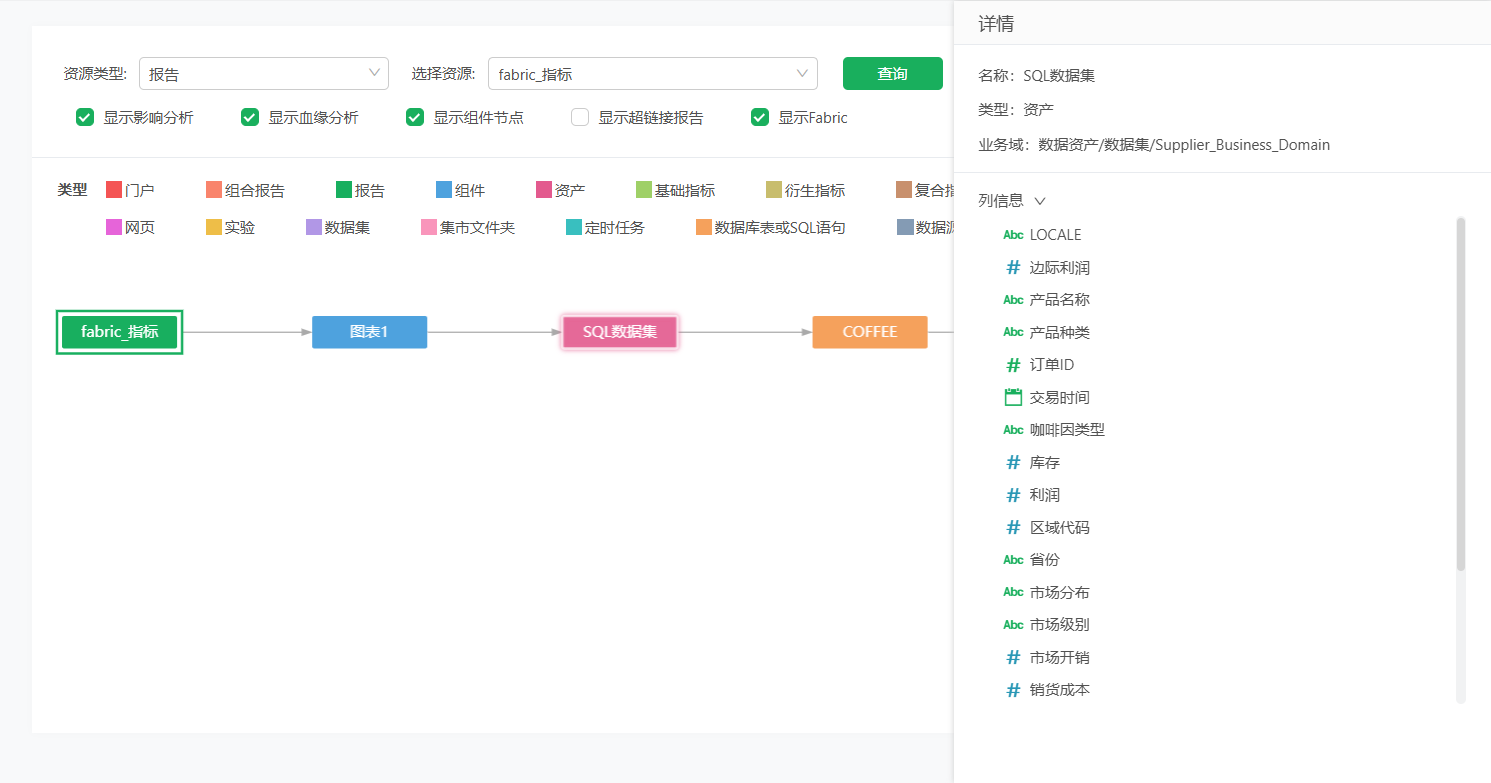
资产 |
包括资产发布名称、血缘节点类型、资产发布的业务域路径以及资产数据集的列信息。
|
2.参数配置
如果是数据库系统,可以配到db.properties里,也可以配到数据库下bihome里的bi.properties里。读取顺序db.properties>bi.properties。
如果是文件系统,则配置到bi.properties里。
•data.lineage.init //默认为true,配置为true时,产品启动时会先解析bihome下面的资源,把它们的血缘关系存储到数据库。
•data.lineage.clear //默认false,在data.lineage.init=true时该属性生效,配置为true时,启动产品时会清除数据库中血缘表的数据。清除动作发生在初始化写入之前。如果想重新生成血缘数据,可以配置此属性。
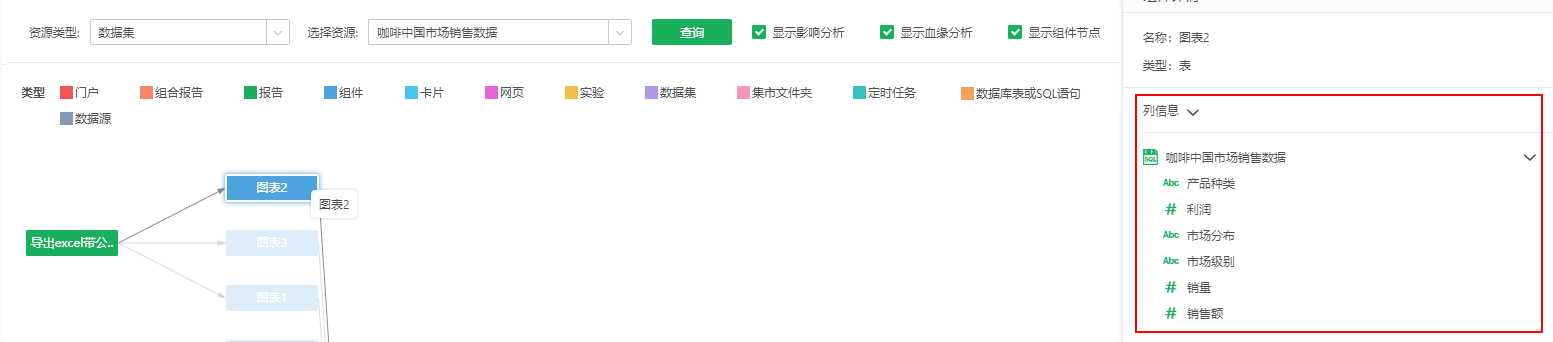
•data.lineage.save.column //默认false,在数据集的血缘图不显示列信息;配置为true时,在组件/数据集节点显示列信息。
例如显示字段信息,如下:
data.lineage.cache.max.size //缓冲池大小,默认3000。通过控制缓冲池的大小,控制内存占用,减少读、写线程对CPU的持续占用。
•data.lineage.write.max.size //写入数据库的行数,默认1000。达到指定的数量会执行commit操作。减少commit的频率。
•data.lineage.debug //默认false,配置为true时在日志管理中显示血缘相关log信息。
•data.lineage.sql.debug //默认为false,配置为true时,打印血缘关系相关SQL执行的时间,一般调试用,开启后会产生大量日志。