

作者: 永洪BI 来源: 永洪科技 时间:2022年06月30日
前几天,朋友问了我一个问题,大概是说,他们正在做一个大数据相关的分析,场景类似这样,每天有大量的酒店入住人的信息,怎么从这些信息中,筛选出某几个人是可能存在某种特定关系的。
(因为真实场景需要保密,所以这里采用类比的方式举例,但是并不妨碍进行进一步的分析。)
听完需求后,我的第一反应就是使用关联规则的算法就可以实现想要得结果。
为了方便朋友理解,我使用Yonghong Desktop软件做了一个案例。
首先准备测试数据。
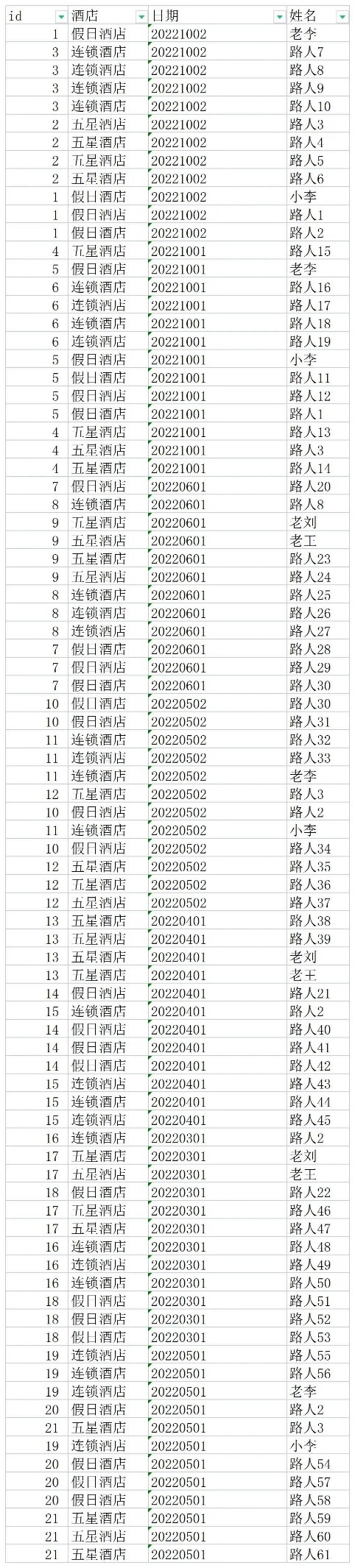
该数据中,同一个酒店和同一个日期入住的人,我们认为属于同一个批次,给与相同的ID进行标识。然后上传到Yonghong Desktop保存为数据集。
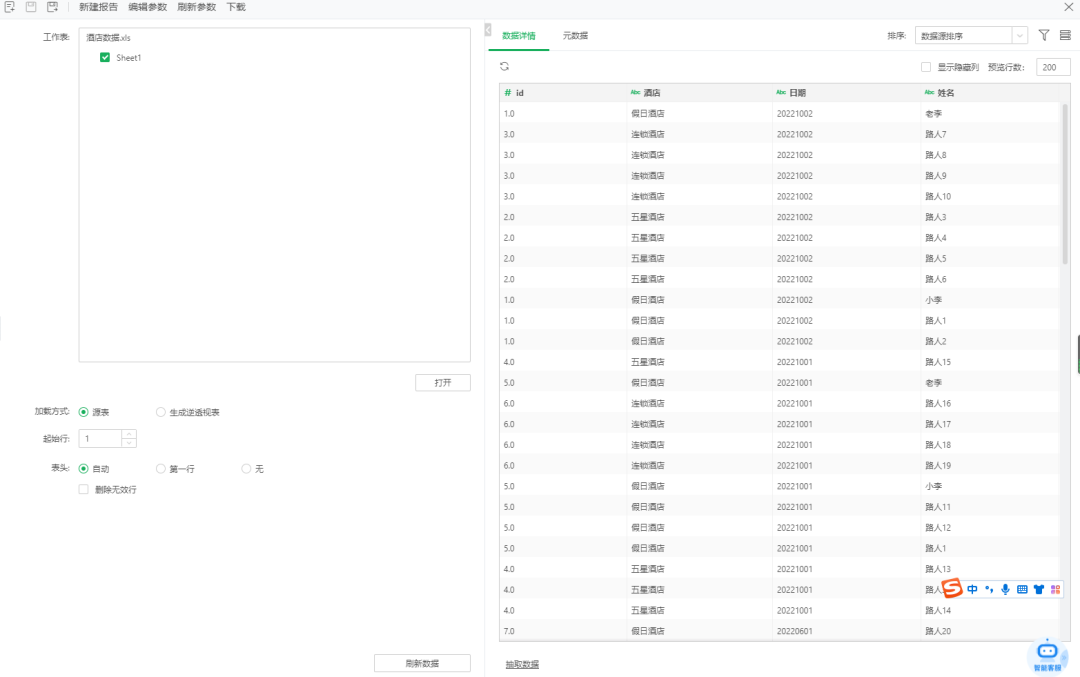
再在深度分析模块新建实验模型,拖入创建好的数据集,再拖入关联规则算法,设置最小支持数和最小置信度,最后再拖入数据集视图。至此,模型建立完毕。是不是特别简单。
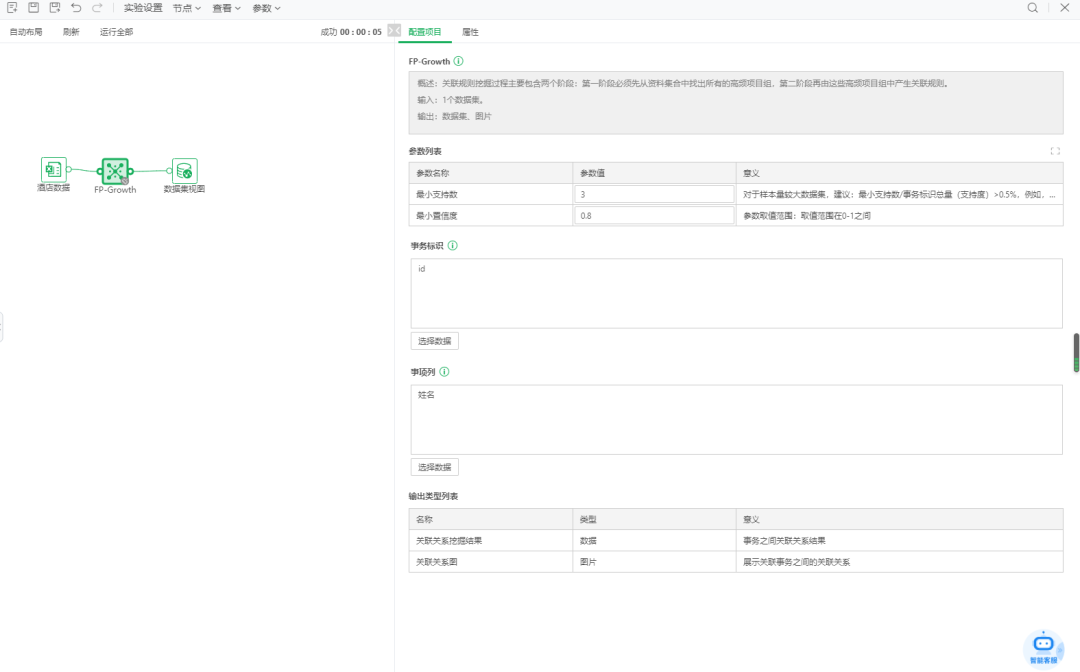
我们运行一下,几秒后遍得到了结果,是不是很惊喜,so easy。
不过接下来就是朋友的四连问。
1:这个结果怎么看?
2:数据维度为什么只有这几个,加几个行吗?
3:数据量大的话,怎么处理?
4:筛选出来的结果集比较大,怎么进一步提取关联结果?
第一个问题
置信度,left 和right, 当 left出现时,right出现的概率,为置信度。
Support 为 left和right ,同时出现的概率,受整体样本行数影响,这个值可能不会太高。最小支持数,数据重复出现的最小次数。
这里我们需要研究的是某人或者某些人之间的关联关系,所以首先置信度要高,再者,left和right一定有关系的话,还必须是充分且必要,也就是说老李出现时,小李一定出现,反之小李出现时,老李一定出现,则我们可以认定他俩存在某种特定的关系。
第二个问题
我们研究的目的是找出可能存在的特定关系,在这个案例中,我们并不关心任何因果关系,只关心概率,也就是说如果反复匹配出现,则认为存在关联关系。所以其他维度可以不要,只要能够标识清楚这个ID和姓名就足够了。
第三个问题
这里需要说回关联规则的一个基本概念,频繁项集,也就是说如果只出现1次,那么他肯定不能算频繁项集。所以数据处理的时候可以直接排除掉只出现1次记录。
最后一个问题,将结果集导入MySQL,再进行SQL处理,表1和表2相同,where 表1.left=表2.right and 表1.right = 表2.left,因为样本数据较少,这里没有做验证。但是理论上应该可以行。
到这里是不是就结束了呢,其实,研究他们的关系还不是最终目的。
这里我提出1种假设,,找出了特定关系的数据后,还不知道它们是哪种特殊关系,怎么办,以本案例来讲,老李和小李,出现的时间是五一和国庆,所以他们大概率是一家人,是出来旅游的,那么就可以有针对性的推旅游线路,酒店,美食,特产相关的信息,也就是精准营销。
至于应该怎么来猜,这里需要回归到第二问题中,把数据放回多维度记录中,去找比较突出的维度(也可以是打标签),或者使用聚类分析(数据多的时候),然后再进行业务解析,这里做聚类和业务解析可能需要下次有机会再进一步展开了。

 400-097-0900
400-097-0900






